For years, pioneering CFOs steadily extended their duties beyond the boundaries of the traditional finance and accounting function. Over the past year, an expanding set of beyond-finance activities – including those related to environmental, social and governance (ESG) matters; human capital reporting; cybersecurity; and supply chain management – have grown in importance for most finance groups. Traditional finance and accounting responsibilities remain core requirements for CFOs, even as they augment planning, analysis, forecasting and reporting processes to thrive in the cloud-based digital era. Protiviti’s latest global survey of CFOs and finance leaders shows that CFOs are refining their new and growing roles by addressing five key areas:
Accessing new data to drive success – The ability of CFOs and finance groups to address their expanding priorities depends on the quality and completeness of the data they access, secure, govern and use. Even the most powerful, cutting-edge tools will deliver subpar insights without optimal data inputs. In addition, more of the data finance uses to generate forward-looking business insights is sourced from producers outside of finance group and the organization. Many of these data producers lack expertise in disclosure controls and therefore need guidance from the finance organization.
Developing long-term strategies for protecting and leveraging data – From a data-protection perspective, CFOs are refining their calculations of cyber risk while benchmarking their organization’s data security and privacy spending and allocations. From a data-leveraging perspective, finance chiefs are creating and updating roadmaps for investments in robotic process automation, business intelligence tools, AI applications, other types of advanced automation, and the cloud technology that serves as a foundational enabler for these advanced finance tools. These investments are designed to satisfy the need for real-time finance insights and analysis among a mushrooming set of internal customers.
Applying financial expertise to ESG reporting – CFOs are mobilizing their team’s financial reporting expertise to address unfolding Human Capital and ESG reporting and disclosure requirements. Leading CFOs are consummating their role in this next-generation data collection activity while ensuring that the organization lays the groundwork to maximize the business value it derives from monitoring, managing and reporting all forms of ESG-related performance metrics.
Elevating and expanding forecasting – Finance groups are overhauling forecasting and planning processes to integrate new data inputs, from new sources, so that the insights the finance organization produces are more real-time in nature and relevant to more finance customers inside and outside the organization. Traditional key performance indicators (KPIs) are being supplemented by key business indicators (KBIs) to provide sharper forecasts and viewpoints. As major new sources of political, social, technological and business volatility arise in an unsteady post-COVID era, forecasting’s value to the organization continues to soar.
Investing in long-term talent strategies – Finance groups are refining their labor model to become more flexible and gain long-term access to cutting-edge skills and innovative thinking in the face of an ongoing and persistent finance and accounting talent crunch. CFOs also are recalibrating their flexible labor models and helping other parts of the organization develop a similar approach to ensure the entire future organization can skill and scale to operate at the right size and in the right manner.
An argument for humility in the face of pandemic forecasting unknown unknowns.
“Are we battling an unprecedented pandemic or panicking at a computer generated mirage?” I asked at the beginning of the COVID-19 pandemic on March 18, 2020. Back then the Imperial College London epidemiological model’s baseline scenario projected that with no changes in individual behaviors and no public health interventions, more than 80 percent of Americans would eventually be infected with novel coronavirus and about 2.2 million would die of the disease. This implies that 0.8 percent of those infected would die of the disease. This is about 8-times worse than the mortality rate from seasonal flu outbreaks.
Spooked by these dire projections, President Donald Trump issued on March 16 his Coronavirus Guidelines for America that urged Americans to “listen to and follow the directions of STATE AND LOCAL AUTHORITIES.” Among other things, Trump’s guidelines pressed people to “work or engage in schooling FROM HOME whenever possible” and “AVOID SOCIAL GATHERINGS in groups of more than 10 people.” The guidelines exhorted Americans to “AVOID DISCRETIONARY TRAVEL, shopping trips and social visits,” and that “in states with evidence of community transmission, bars, restaurants, food courts, gyms, and other indoor and outdoor venues where people congregate should be closed.”
Let’s take a moment to recognize just how blindly through the early stages of the pandemic we—definitely including our public health officials—were all flying at the time. The guidelines advised people to frequently wash their hands, disinfect surfaces, and avoid touching their faces. Basically, these were the sort of precautions typically recommended for influenza outbreaks. On July 9, 2020, an open letter from 239 researchers begged the World Health Organization and other public health authorities to recognize that COVID-19 was chiefly spread by airborne transmission rather than via droplets deposited on surfaces. The U.S. Centers for Disease Control and Prevention (CDC) didn’t update its guidance on COVID-19 airborne transmission until May 2021. And it turns out that touching surfaces is not a major mode of transmission for COVID-19.
The president’s guidelines also advised, “IF YOU FEEL SICK, stay home. Do not go to work.” This sensible advice, however, missed the fact that a huge proportion of COVID-19 viral transmission occurred from people without symptoms. That is, people who feel fine can still be infected and, unsuspectingly, pass along their virus to others. For example, one January 2021 study estimated that “59% of all transmission came from asymptomatic transmission, comprising 35% from presymptomatic individuals and 24% from individuals who never develop symptoms.”
The Imperial College London’s alarming projections did not go uncontested. A group of researchers led by Stanford University medical professor Jay Bhattacharya believed that COVID-19 infections were much more widespread than the reported cases indicated. If the Imperial College London’s hypothesis were true, Bhattacharya and his fellow researchers argued, that would mean that the mortality rate and projected deaths from the coronavirus would be much lower, making the pandemic much less menacing.
The researchers’ strategy was to blood test people in Santa Clara and Los Angeles Counties in California to see how many had already developed antibodies in response to coronavirus infections. Using those data, they then extrapolated what proportion of county residents had already been exposed to and recovered from the virus.
Bhattacharya and his colleagues preliminarily estimated that between 48,000 and 81,000 people had already been infected in Santa Clara County by early April, which would mean that COVID-19 infections were “50-85-fold more than the number of confirmed cases.” Based on these data the researchers calculated that toward the end of April “a hundred deaths out of 48,000-81,000 infections corresponds to an infection fatality rate of 0.12-0.2%.” As I optimistically reported at the time, that would imply that COVID-19’s lethality was not much different than for seasonal influenza.
Bhattacharya and his colleagues conducted a similar antibody survey in Los Angeles County. That study similarly asserted that COVID-19 infections were much more widespread than reported cases. The study estimated 2.8 to 5.6 percent of the residents of Los Angeles County had been infected by early April. That translates to approximately 221,000 to 442,000 adults in the county who have had the infection. “That estimate is 28 to 55 times higher than the 7,994 confirmed cases of COVID-19 reported to the county by the time of the study in early April,” noted the accompanying press release. “The number of COVID-related deaths in the county has now surpassed 600.” These estimates would imply a relatively low infection fatality rate of between 0.14 and 0.27 percent.
Unfortunately, from the vantage of 14 months, those hopeful results have not been borne out. Santa Clara County public health officials report that there have been 119,712 diagnosed cases of COVID-19 so far. If infections were really being underreported by 50-fold, that would suggest that roughly 6 million Santa Clara residents would by now have been infected by the coronavirus. The population of the county is just under 2 million. Alternatively, extrapolating a 50-fold undercount would imply that when 40,000 diagnosed cases were reported on July 11, 2020, all 2 million people living in Santa Clara County had been infected by that date.
Los Angeles County reports 1,247,742 diagnosed COVID-19 cases cumulatively. Again, if infections were really being underreported 28-fold, that would imply that roughly 35 million Angelenos out of a population of just over 10 million would have been infected with the virus by now. Again turning the 28-fold estimate on its head, that would imply that all 10 million Angelenos would have been infected when 360,000 cases had been diagnosed on November 21, 2020.
COVID-19 cases are, of course, being undercounted. Data scientist Youyang Gu has been consistently more accurate than many of the other researchers parsing COVID-19 pandemic trends. Gu estimates that over the course of the pandemic, U.S. COVID-19 infections have roughly been 4-fold greater than diagnosed cases. Applying that factor to the number of reported COVID-19 cases would yield an estimate of 480,000 and 5,000,000 total infections in Santa Clara and Los Angeles respectively. If those are ballpark accurate, that would mean that the COVID-19 infection fatality rate in Santa Clara is 0.46 percent and is 0.49 percent in Los Angeles. Again, applying a 4-fold multiplier to take account of undercounted infections, those are both just about where the U.S. infection fatality rate of 0.45 percent is now.
The upshot is that, so far, we have ended up about half-way between the best case and worst case scenarios sketched out at the beginning of the pandemic.
We rarely see the impact of policies reflected in data in real time. The COVID-19 pandemic changed that. In the present moment, a range of government, private, and academic sources catalogue household-level health and economic information to enable rapid policy analysis and response. To continue promoting periodic findings, identifying vulnerable populations, and maintaining a focus on public health, frequent national data collection needs to be improved and expanded permanently.
Knowledge accumulates over time, facilitating new advancements and advocacy. While mRNA biotechnology was not usable decades ago, years of public research helped unlock highly effective COVID-19 vaccines. The same can be true for advancing effective socioeconomic policies. More national, standardized data like the Census Bureau’s Household Pulse Survey will accelerate progress. At the same time, there are significant issues with national data sources. For instance, COVID-19 data reported by the CDC faced notable quality issues and inconsistencies between states.
Policymakers can’t address problems that they don’t know exist. Researchers can’t identify problems and solutions without adequate data. We can better study how policies impact population health and inform legislative action with greater federal funding dedicated to wide-ranging, systematized population surveys.
Broader data collection enables more findings and policy development
Evidence-based research is at the core of effective policy action. Surveillance data indicates what problems families face, who is most affected, and which interventions can best promote health and economic well-being. These collections can inform policy responses by reporting information on the demographics disproportionately affected by socioeconomic disruptions. Race and ethnicity, age, gender, sexual orientation, household composition, and work occupation all provide valuable details on who has been left behind by past and present legislative choices.
Since March 2020, COVID-19 cases and deaths, changes in employment, and food and housing security have been tracked periodically with detailed demographic information through surveys like the Both cumulative statistical compilations and representative surveillance polling have been instrumental to analyses. Our team has recorded over 200 state-level policies in the COVID-19 US State Policy (CUSP) database to further research and journalistic investigations. We have learned a number of policy lessons, from the health protections of eviction moratoria to the food security benefits of social insurance expansions. Not to be forgotten is the importance of documented evidence to these insights.
Without this comprehensive tracking, it would be difficult to determine the number of evictions occurring despite active moratoria, what factors contribute to elevated risk of COVID-19, and the value of pandemic unemployment insurance programs in states. The wider number of direct and indirect health outcomes measured have bolstered our understanding of the suffering experienced by different demographic groups. These issues are receiving legislative attention, in no small part due to the broad statistical collection and subsequent analytical research on these topics.
Insufficient data results in inadequate understanding of policy issues
The more high-quality data there is, the better. With the state-level policies present in CUSP, our team and other research groups quantified the impact of larger unemployment insurance benefit sizes, greater minimum wages, mask mandates, and eviction freezes. These analyses have been utilized by state and federal officials. None would have been possible without increased data collection.
However, our policy investigations are constrained by the data availability and quality on state and federal government websites, which may be improved with stimulus funds allocated to modernize our public health data infrastructure. Some of the most consequential decision-making right now relates to vaccine distribution and administration, but it is difficult to disaggregate state-level statistics. Many states lack demographic information on vaccine recipients as well as those that have contracted or died from COVID-19. Even though racial disparities are present in COVID-19 cases, hospitalizations, and deaths nationally, we can’t always determine the extent of these inequities locally. These present issues are a microcosm of pre-existing problems.
Data shortcomings present for years, in areas like occupational safety, are finally being spotlighted due to the pandemic. Minimal national and state workplace health data translated to insufficient COVID-19 surveillance in workplace settings. Studies that show essential workers are facing elevated risk of COVID-19 are often limited in scope to individual states or cities, largely due to the lack of usable and accessible data. More investment is needed going forward beyond the pandemic to better document a Otherwise there will continue to be serious blind spots in the ability to evaluate policy decisions, enforce better workplace standards, and hold leaders accountable for choices.
These are problems with a simple solution: collect more information. Now is not the time to eliminate valuable community surveys and aggregate compilations, but to expand on them. More comprehensive data will provide a spotlight on current and future legislative choices and improve the understanding of policies in new ways. It is our hope that are built upon and become the new norm.
Disclosure: Funding received from Robert Wood Johnson Foundation was used to develop the COVID-19 US State Policy Database.
Of 26 health systems surveyed by MedCity News, nearly half used automated tools to respond to the Covid-19 pandemic, but none of them were regulated. Even as some hospitals continued using these algorithms, experts cautioned against their use in high-stakes decisions.
A year ago, Michigan Medicine faced a dire situation. In March of 2020, the health system predicted it would have three times as many patients as its 1,000-bed capacity — and that was the best-case scenario. Hospital leadership prepared for this grim prediction by opening a field hospital in a nearby indoor track facility, where patients could go if they were stable, but still needed hospital care. But they faced another predicament: How would they decide who to send there?
Two weeks before the field hospital was set to open, Michigan Medicine decided to use a risk model developed by Epic Systems to flag patients at risk of deterioration. Patients were given a score of 0 to 100, intended to help care teams determine if they might need an ICU bed in the near future. Although the model wasn’t developed specifically for Covid-19 patients, it was the best option available at the time, said Dr. Karandeep Singh, an assistant professor of learning health sciences at the University of Michigan and chair of Michigan Medicine’s clinical intelligence committee. But there was no peer-reviewed research to show how well it actually worked.
Researchers tested it on over 300 Covid-19 patients between March and May. They were looking for scores that would indicate when patients would need to go to the ICU, and if there was a point where patients almost certainly wouldn’t need intensive care.
“We did find a threshold where if you remained below that threshold, 90% of patients wouldn’t need to go to the ICU,” Singh said. “Is that enough to make a decision on? We didn’t think so.”
But if the number of patients were to far exceed the health system’s capacity, it would be helpful to have some way to assist with those decisions.
“It was something that we definitely thought about implementing if that day were to come,” he said in a February interview.
Thankfully, that day never came.
The survey Michigan Medicine is one of 80 hospitals contacted by MedCity News between January and April in a survey of decision-support systems implemented during the pandemic. Of the 26 respondents, 12 used machine learning tools or automated decision systems as part of their pandemic response. Larger hospitals and academic medical centers used them more frequently.
Faced with scarcities in testing, masks, hospital beds and vaccines, several of the hospitals turned to models as they prepared for difficult decisions. The deterioration index created by Epic was one of the most widely implemented — more than 100 hospitals are currently using it — but in many cases, hospitals also formulated their own algorithms.
They built models to predict which patients were most likely to test positive when shortages of swabs and reagents backlogged tests early in the pandemic. Others developed risk-scoring tools to help determine who should be contacted first for monoclonal antibody treatment, or which Covid patients should be enrolled in at-home monitoring programs.
MedCity News also interviewed hospitals on their processes for evaluating software tools to ensure they are accurate and unbiased. Currently, the FDA does not require some clinical decision-support systems to be cleared as medical devices, leaving the developers of these tools and the hospitals that implement them responsible for vetting them.
Among the hospitals that published efficacy data, some of the models were only evaluated through retrospective studies. This can pose a challenge in figuring out how clinicians actually use them in practice, and how well they work in real time. And while some of the hospitals tested whether the models were accurate across different groups of patients — such as people of a certain race, gender or location — this practice wasn’t universal.
As more companies spin up these models, researchers cautioned that they need to be designed and implemented carefully, to ensure they don’t yield biased results.
An ongoing review of more than 200 Covid-19 risk-prediction models found that the majority had a high risk of bias, meaning the data they were trained on might not represent the real world.
“It’s that very careful and non-trivial process of defining exactly what we want the algorithm to be doing,” said Ziad Obermeyer, an associate professor of health policy and management at UC Berkeley who studies machine learning in healthcare. “I think an optimistic view is that the pandemic functions as a wakeup call for us to be a lot more careful in all of the ways we’ve talked about with how we build algorithms, how we evaluate them, and what we want them to do.”
Algorithms can’t be a proxy for tough decisions Concerns about bias are not new to healthcare. In a paper published two years ago, Obermeyer found a tool used by several hospitals to prioritize high-risk patients for additional care resources was biased against Black patients. By equating patients’ health needs with the cost of care, the developers built an algorithm that yielded discriminatory results.
More recently, a rule-based system developed by Stanford Medicine to determine who would get the Covid-19 vaccine first ended up prioritizing administrators and doctors who were seeing patients remotely, leaving out most of its 1,300 residents who had been working on the front lines. After an uproar, the university attributed the errors to a “complex algorithm,” though there was no machine learning involved.
Both examples highlight the importance of thinking through what exactly a model is designed to do — and not using them as a proxy to avoid the hard questions.
“The Stanford thing was another example of, we wanted the algorithm to do A, but we told it to do B. I think many health systems are doing something similar,” Obermeyer said. “You want to give the vaccine first to people who need it the most — how do we measure that?”
The urgency that the pandemic created was a complicating factor. With little information and few proven systems to work with in the beginning, health systems began throwing ideas at the wall to see what works. One expert questioned whether people might be abdicating some responsibility to these tools.
“Hard decisions are being made at hospitals all the time, especially in this space, but I’m worried about algorithms being the idea of where the responsibility gets shifted,” said Varoon Mathur, a technology fellow at NYU’s AI Now Institute, in a Zoom interview. “Tough decisions are going to be made, I don’t think there are any doubts about that. But what are those tough decisions? We don’t actually name what constraints we’re hitting up against.”
The wild, wild west There currently is no gold standard for how hospitals should implement machine learning tools, and little regulatory oversight for models designed to support physicians’ decisions, resulting in an environment that Mathur described as the “wild, wild west.”
How these systems were used varied significantly from hospital to hospital.
Early in the pandemic, Cleveland Clinic used a model to predict which patients were most likely to test positive for the virus as tests were limited. Researchers developed it using health record data from more than 11,000 patients in Ohio and Florida, including 818 who tested positive for Covid-19. Later, they created a similar risk calculator to determine which patients were most likely to be hospitalized for Covid-19, which was used to prioritize which patients would be contacted daily as part of an at-home monitoring program.
Initially, anyone who tested positive for Covid-19 could enroll in this program, but as cases began to tick up, “you could see how quickly the nurses and care managers who were running this program were overwhelmed,” said Dr. Lara Jehi, Chief Research Information Officer at Cleveland Clinic. “When you had thousands of patients who tested positive, how could you contact all of them?”
While the tool included dozens of factors, such as a patient’s age, sex, BMI, zip code, and whether they smoked or got their flu shot, it’s also worth noting that demographic information significantly changed the results. For example, a patient’s race “far outweighs” any medical comorbidity when used by the tool to estimate hospitalization risk, according to a paper published in Plos One. Cleveland Clinic recently made the model available to other health systems.
Others, like Stanford Health Care and 731-bed Santa Clara County Medical Center, started using Epic’s clinical deterioration index before developing their own Covid-specific risk models. At one point, Stanford developed its own risk-scoring tool, which was built using past data from other patients who had similar respiratory diseases, such as the flu, pneumonia, or acute respiratory distress syndrome. It was designed to predict which patients would need ventilation within two days, and someone’s risk of dying from the disease at the time of admission.
Stanford tested the model to see how it worked on retrospective data from 159 patients that were hospitalized with Covid-19, and cross-validated it with Salt Lake City-based Intermountain Healthcare, a process that took several months. Although this gave some additional assurance — Salt Lake City and Palo Alto have very different populations, smoking rates and demographics — it still wasn’t representative of some patient groups across the U.S.
“Ideally, what we would want to do is run the model specifically on different populations, like on African Americans or Hispanics and see how it performs to ensure it’s performing the same for different groups,” Tina Hernandez-Boussard, an associate professor of medicine, biomedical data science and surgery at Stanford, said in a February interview. “That’s something we’re actively seeking. Our numbers are still a little low to do that right now.”
Stanford planned to implement the model earlier this year, but ultimately tabled it as Covid-19 cases fell.
‘The target is moving so rapidly’ Although large medical centers were more likely to have implemented automated systems, there were a few notable holdouts. For example, UC San Francisco Health, Duke Health and Dignity Health all said they opted not to use risk-prediction models or other machine learning tools in their pandemic responses.
“It’s pretty wild out there and I’ll be honest with you — the dynamics are changing so rapidly,” said Dr. Erich Huang, chief officer for data quality at Duke Health and director of Duke Forge. “You might have a model that makes sense for the conditions of last month but do they make sense for the conditions of next month?”
That’s especially true as new variants spread across the U.S., and more adults are vaccinated, changing the nature and pace of the disease. But other, less obvious factors might also affect the data. For instance, Huang pointed to big differences in social mobility across the state of North Carolina, and whether people complied with local restrictions. Differing social and demographic factors across communities, such as where people work and whether they have health insurance, can also affect how a model performs.
“There are so many different axes of variability, I’d feel hard pressed to be comfortable using machine learning or AI at this point in time,” he said. “We need to be careful and understand the stakes of what we’re doing, especially in healthcare.”
Leadership at one of the largest public hospitals in the U.S., 600-bed LAC+USC Medical Center in Los Angeles, also steered away from using predictive models, even as it faced an alarming surge in cases over the winter months.
At most, the hospital used alerts to remind physicians to wear protective equipment when a patient has tested positive for Covid-19.
“My impression is that the industry is not anywhere near ready to deploy fully automated stuff just because of the risks involved,” said Dr. Phillip Gruber, LAC+USC’s chief medical information officer. “Our institution and a lot of institutions in our region are still focused on core competencies. We have to be good stewards of taxpayer dollars.”
When the data itself is biased Developers have to contend with the fact that any model developed in healthcare will be biased, because the data itself is biased; how people access and interact with health systems in the U.S. is fundamentally unequal.
How that information is recorded in electronic health record systems (EHR) can also be a source of bias, NYU’s Mathur said. People don’t always self-report their race or ethnicity in a way that fits neatly within the parameters of an EHR. Not everyone trusts health systems, and many people struggle to even access care in the first place.
“Demographic variables are not going to be sharply nuanced. Even if they are… in my opinion, they’re not clean enough or good enough to be nuanced into a model,” Mathur said.
The information hospitals have had to work with during the pandemic is particularly messy. Differences in testing access and missing demographic data also affect how resources are distributed and other responses to the pandemic.
“It’s very striking because everything we know about the pandemic is viewed through the lens of number of cases or number of deaths,” UC Berkeley’s Obermeyer said. “But all of that depends on access to testing.”
At the hospital level, internal data wouldn’t be enough to truly follow whether an algorithm to predict adverse events from Covid-19 was actually working. Developers would have to look at social security data on mortality, or whether the patient went to another hospital, to track down what happened.
“What about the people a physician sends home — if they die and don’t come back?” he said.
Researchers at Mount Sinai Health System tested a machine learning tool to predict critical events in Covid-19 patients — such as dialysis, intubation or ICU admission — to ensure it worked across different patient demographics. But they still ran into their own limitations, even though the New York-based hospital system serves a diverse group of patients.
They tested how the model performed across Mount Sinai’s different hospitals. In some cases, when the model wasn’t very robust, it yielded different results, said Benjamin Glicksberg, an assistant professor of genetics and genomic sciences at Mount Sinai and a member of its Hasso Plattner Institute for Digital Health.
They also tested how it worked in different subgroups of patients to ensure it didn’t perform disproportionately better for patients from one demographic.
“If there’s a bias in the data going in, there’s almost certainly going to be a bias in the data coming out of it,” he said in a Zoom interview. “Unfortunately, I think it’s going to be a matter of having more information that can approximate these external factors that may drive these discrepancies. A lot of that is social determinants of health, which are not captured well in the EHR. That’s going to be critical for how we assess model fairness.”
Even after checking for whether a model yields fair and accurate results, the work isn’t done yet. Hospitals must continue to validate continuously to ensure they’re still working as intended — especially in a situation as fast-moving as a pandemic.
A bigger role for regulators All of this is stirring up a broader discussion about how much of a role regulators should have in how decision-support systems are implemented.
Of the hospitals surveyed by MedCity News, none of the models they developed had been cleared by the FDA, and most of the external tools they implemented also hadn’t gone through any regulatory review.
“My experience suggests that most models are put into practice with very little evidence of their effects on outcomes because they are presumed to work, or at least to be more efficient than other decision-making processes,” Kellie Owens, a researcher for Data & Society, a nonprofit that studies the social implications of technology, wrote in an email. “I think we still need to develop better ways to conduct algorithmic risk assessments in medicine. I’d like to see the FDA take a much larger role in regulating AI and machine learning models before their implementation.”
Developers should also ask themselves if the communities they’re serving have a say in how the system is built, or whether it is needed in the first place. The majority of hospitals surveyed did not share with patients if a model was used in their care or involve patients in the development process.
In some cases, the best option might be the simplest one: don’t build.
In the meantime, hospitals are left to sift through existing published data, preprints and vendor promises to decide on the best option. To date, Michigan Medicine’s paper is still the only one that has been published on Epic’s Deterioration Index.
Care teams there used Epic’s score as a support tool for its rapid response teams to check in on patients. But the health system was also looking at other options.
“The short game was that we had to go with the score we had,” Singh said. “The longer game was, Epic’s deterioration index is proprietary. That raises questions about what is in it.”
Optum, a subsidiary of UnitedHealth, provides data analytics and infrastructure, a pharmacy benefit manager called OptumRx, a bank providing patient loans called Optum Bank, and more.
It’s not often that the American Hospital Association—known for fun lobbying tricks like hiring consultants to create studies showing the benefits of hospital mergers—directly goes after another consolidation in the industry.
But when the AHA caught wind of UnitedHealth Group subsidiary Optum’s plans, announced in January 2021, to acquire data analytics firm Change Healthcare, they offered up some fiery language in a letter to the Justice Department. “The acquisition … will concentrate an immense volume of competitively sensitive data in the hands of the most powerful health insurance company in the United States, with substantial clinical provider and health insurance assets, and ultimately removes a neutral intermediary.”
If permitted to go through, Optum’s acquisition of Change would fundamentally alter both the health data landscape and the balance of power in American health care. UnitedHealth, the largest health care corporation in the U.S., would have access to all of its competitors’ business secrets. It would be able to self-preference its own doctors. It would be able to discriminate, racially and geographically, against different groups seeking insurance. None of this will improve public health; all of it will improve the profits of Optum and its corporate parent.
Despite the high stakes, Optum has been successful in keeping this acquisition out of the public eye.Part of this PR success is because few health care players want to openly oppose an entity as large and powerful as UnitedHealth. But perhaps an even larger part is that few fully understand what this acquisition will mean for doctors, patients, and the health care system at large.
If regulators allow the acquisition to take place, Optum will suddenly have access to some of the most secret data in health care.
UnitedHealth is the largest health care entity in the U.S., using several metrics. United Healthcare (the insurance arm) is the largest health insurer in the United States, with over 70 million members, 6,500 hospitals, and 1.4 million physicians and other providers. Optum, a separate subsidiary, provides data analytics and infrastructure, a pharmacy benefit manager called OptumRx, a bank providing patient loans called Optum Bank, and more. Through Optum, UnitedHealth also controls more than 50,000 affiliated physicians, the largest collection of physicians in the country.
While UnitedHealth as a whole has earned a reputation for throwing its weight around the industry, Optum has emerged in recent years as UnitedHealth’s aggressive acquisition arm. Acquisitions of entities as varied as DaVita’s dialysis physicians, MedExpress urgent care, and Advisory Board Company’s consultants have already changed the health care landscape. As Optum gobbles up competitors, customers, and suppliers, it has turned into UnitedHealth’s cash cow, bringing in more than 50 percent of the entity’s annual revenue.
On a recent podcast, Chas Roades and Dr. Lisa Bielamowicz of Gist Healthcare described Optum in a way that sounds eerily similar to a single-payer health care system. “If you think about what Optum is assembling, they are pulling together now the nation’s largest employers of docs, owners of one of the country’s largest ambulatory surgery center chains, the nation’s largest operator of urgent care clinics,” said Bielamowicz. With 98 million customers in 2020, OptumHealth, just one branch of Optum’s services, had eyes on roughly 30 percent of the U.S. population. Optum is, Roades noted, “increasingly the thing that ate American health care.”
Optum has not been shy about its desire to eventually assemble all aspects of a single-payer system under its own roof. “The reason it’s been so hard to make health care and the health-care system work better in the United States is because it’s rare to have patients, providers—especially doctors—payers, and data, all brought together under an organization,” OptumHealth CEO Wyatt Decker told Bloomberg. “That’s the rare combination that we offer. That’s truly a differentiator in the marketplace.” The CEO of UnitedHealth, Andrew Witty, has also expressed the corporation’s goal of “wir[ing] together” all of UnitedHealth’s assets.
Controlling Change Healthcare would get UnitedHealth one step closer to creating their private single-payer system. That’s why UnitedHealth is offering up $13 billion, a 41 percent premium on the public valuation of Change. But here’s why that premium may be worth every penny.
Change Healthcare is Optum’s leading competitor in pre-payment claims integrity; functionally, a middleman service that allows insurers to process provider claims (the receipts from each patient visit) and address any mistakes. To clarify what that looks like in practice, imagine a patient goes to an in-network doctor for an appointment. The doctor performs necessary procedures and uses standardized codes to denote each when filing a claim for reimbursement from the patient’s insurance coverage. The insurer then hires a reviewing service—this is where Change comes in—to check these codes for accuracy. If errors are found in the coded claims, such as accidental duplications or more deliberate up-coding (when a doctor intentionally makes a patient seem sicker than they are), Change will flag them, saving the insurer money.
The most obvious potential outcome of the merger is that the flow of data will allow Optum/UnitedHealth to preference their own entities and physicians above others.
To accurately review the coded claims, Change’s technicians have access to all of their clients’ coverage information, provider claims data, and the negotiated rates that each insurer pays.
Change also provides other services, including handling the actual payments from insurers to physicians, reimbursing for services rendered. In this role, Change has access to all of the data that flows between physicians and insurers and between pharmacies and insurers—both of which give insurers leverage when negotiating contracts. Insurers often send additional suggestions to Change as well; essentially their commercial secrets on how the insurer is uniquely saving money. Acquiring Change could allow Optum to see all of this.
Change’s scale (and its independence from payers) has been a selling point; just in the last few months of 2020, the corporation signed multiple contracts with the largest payers in the country.
Optum is not an independent entity; as mentioned above, it’s owned by the largest insurer in the U.S. So, when insurers are choosing between the only two claims editors that can perform at scale and in real time, there is a clear incentive to use Change, the independent reviewer, over Optum, a direct competitor.
If regulators allow the acquisition to take place, Optum will suddenly have access to some of the most secret data in health care. In other words, if the acquisition proceeds and Change is owned by UnitedHealth, the largest health care corporation in the U.S. will own the ability to peek into the book of business for every insurer in the country.
Although UnitedHealth and Optum claim to be separate entities with firewalls that safeguard against anti-competitive information sharing, the porosity of the firewall is an open question. As the AHA pointed out in their letter to the DOJ, “[UnitedHealth] has never demonstrated that the firewalls are sufficiently robust to prevent sensitive and strategic information sharing.”
In some cases, this “firewall” would mean asking Optum employees to forget their work for UnitedHealth’s competitors when they turn to work on implementing changes for UnitedHealth. It is unlikely to work. And that is almost certainly Optum’s intention.
The most obvious potential outcome of the merger is that the flow of data will allow Optum/UnitedHealth to preference their own entities and physicians above others. This means that doctors (and someday, perhaps, hospitals) owned by the corporation will get better rates, funded by increased premiums on patients. Optum drugs might seem cheaper, Optum care better covered. Meanwhile, health care costs will continue to rise as UnitedHealth fuels executive salaries and stock buybacks.
UnitedHealth has already been accused of self-preferencing. A large group of anesthesiologists filed suit in two states last week, accusing the company of using perks to steer surgeons into using service providers within its networks.
Even if UnitedHealth doesn’t purposely use data to discriminate, the corporation has been unable to correct for racially biased data in the past.
Beyond this obvious risk, the data alterations caused by the Change acquisition could worsen existing discrimination and medical racism. Prior to the acquisition, Change launched a geo-demographic analytics unit. Now, UnitedHealth will have access to that data, even as it sells insurance to different demographic categories and geographic areas.
Even if UnitedHealth doesn’t purposely use data to discriminate, the corporation has been unable to correct for racially biased data in the past, and there’s no reason to expect it to do so in the future. A study published in 2019 found that Optum used a racially biased algorithm that could have led to undertreating Black patients. This is a problem for all algorithms. As data scientist Cathy O’Neil told 52 Insights, “if you have a historically biased data set and you trained a new algorithm to use that data set, it would just pick up the patterns.” But Optum’s size and centrality in American health care would give any racially biased algorithms an outsized impact. And antitrust lawyer Maurice Stucke noted in an interview that using racially biased data could be financially lucrative. “With this data, you can get people to buy things they wouldn’t otherwise purchase at the highest price they are willing to pay … when there are often fewer options in their community, the poor are often charged a higher price.”
The fragmentation of American health care has kept Big Data from being fully harnessed as it is in other industries, like online commerce. But Optum’s acquisition of Change heralds the end of that status quo and the emergence of a new “Big Tech” of health care. With the Change data, Optum/UnitedHealth will own the data, providers, and the network through which people receive care. It’s not a stretch to see an analogy to Amazon, and how that corporation uses data from its platform to undercut third parties while keeping all its consumers in a panopticon of data.
The next step is up to the Department of Justice, which has jurisdiction over the acquisition (through an informal agreement, the DOJ monitors health insurance and other industries, while the FTC handles hospital mergers, pharmaceuticals, and more). The longer the review takes, the more likely it is that the public starts to realize that, as Dartmouth health policy professor Dr. Elliott Fisher said, “the harms are likely to outweigh the benefits.”
There are signs that the DOJ knows that to approve this acquisition is to approve a new era of vertical integration. In a document filed on March 24, Change informed the SEC that the DOJ had requested more information and extended its initial 30-day review period. But the stakes are high. If the acquisition is approved, we face a future in which UnitedHealth/Optum is undoubtedly “the thing that ate American health care.”
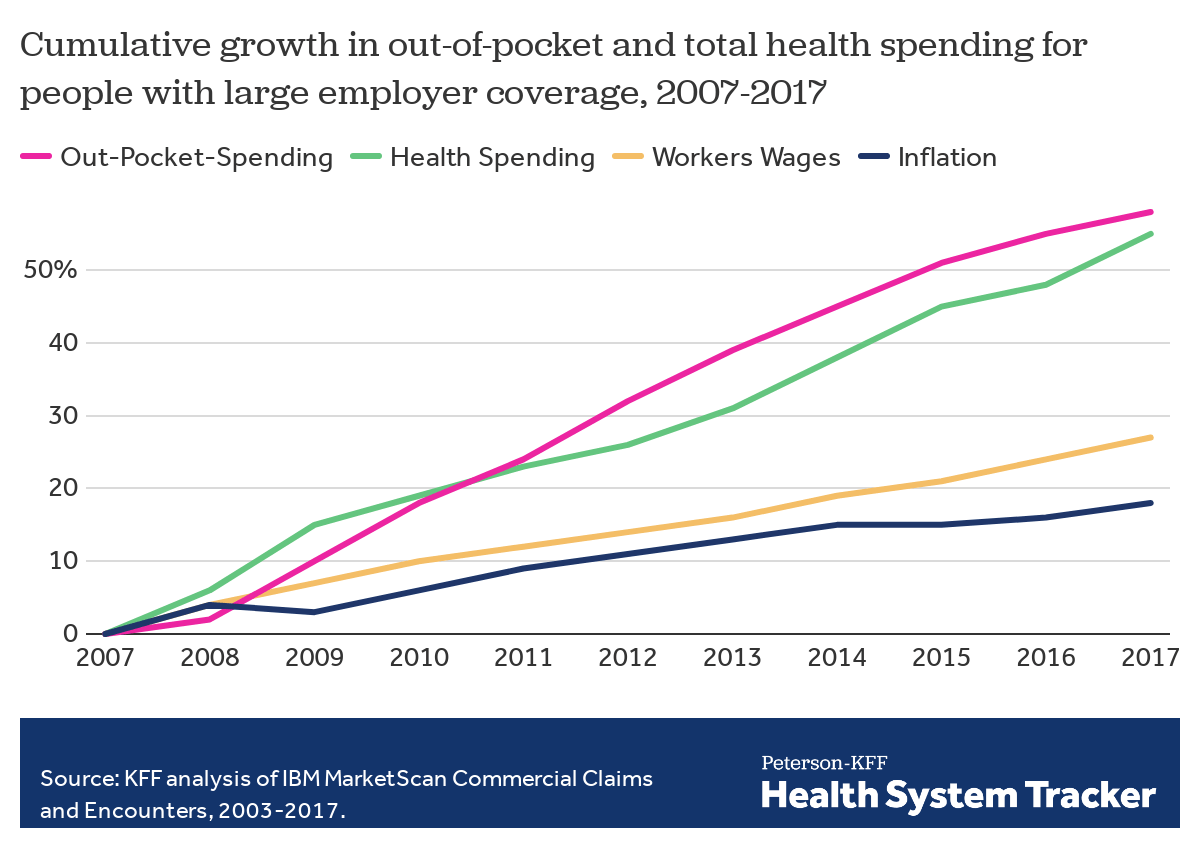
Employers — including companies, state governments and universities — purchase health care on behalf of roughly 150 million Americans. The cost of that care has continued to climb for both businesses and their workers.
For many years, employers saw wasteful care as the primary driver of their rising costs. They made benefits changes like adding wellness programs and raising deductibles to reduce unnecessary care, but costs continued to rise. Now, driven by a combination of new research and changing market forces — especially hospital consolidation — more employers see prices as their primary problem.
By amassing and analyzing employers’ claims data in innovative ways, academics and researchers at organizations like the Health Care Cost Institute (HCCI) and RAND have helped illuminate for employers two key truths about the hospital-based health care they purchase:
1) PRICES VARY WIDELY FOR THE SAME SERVICES
Data show that providers charge private payers very different prices for the exact same services — even within the same geographic area.
For example, HCCI found the price of a C-section delivery in the San Francisco Bay Area varies between hospitals by as much as:$24,107
Data show that hospitals charge employers and private insurers, on average, roughly twice what they charge Medicare for the exact same services. A recent RAND study analyzed more than 3,000 hospitals’ prices and found the most expensive facility in the country charged employers:4.1xMedicare
Hospitals claim this price difference is necessary because public payers like Medicare do not pay enough. However, there is a wide gap between the amount hospitals lose on Medicare (around -9% for inpatient care) and the amount more they charge employers compared to Medicare (200% or more).
Employer Efforts
A small but growing group of companies, public employers (like state governments and universities) and unions is using new data and tactics to tackle these high prices. (Learn more about who’s leading this work, how and why by listening to our full podcast episode in the player above.)
Note that the employers leading this charge tend to be large and self-funded, meaning they shoulder the risk for the insurance they provide employees, giving them extra flexibility and motivation to purchase health care differently. The approaches they are taking include:
Steering Employees
Some employers are implementing so-called tiered networks, where employees pay more if they want to continue seeing certain, more expensive providers. Others are trying to strongly steer employees to particular hospitals, sometimes know as centers of excellence, where employers have made special deals for particular services.
Purdue University, for example, covers travel and lodging and offers a $500 stipend to employees that get hip or knee replacements done at one Indiana hospital.
Negotiating New Deals
There is a movement among some employers to renegotiate hospital deals using Medicare rates as the baseline — since they are transparent and account for hospitals’ unique attributes like location and patient mix — as opposed to negotiating down from charges set by hospitals, which are seen by many as opaque and arbitrary. Other employers are pressuring their insurance carriers to renegotiate the contracts they have with hospitals.
In 2016, the Montana state employee health plan, led by Marilyn Bartlett, got all of the state’s hospitals to agree to a payment rate based on a multiple of Medicare. They saved more than $30 million in just three years. Bartlett is now advising other states trying to follow her playbook.
In 2020, several large Indiana employers urged insurance carrier Anthem to renegotiate their contract with Parkview Health, a hospital system RAND researchers identified as one of the most expensive in the country. After months of tense back-and-forth, the pair reached a five-year deal expected to save Anthem customers $700 million.
Legislating, Regulating, Litigating
Some employer coalitions are advocating for more intervention by policymakers to cap health care prices or at least make them more transparent. States like Colorado and Indiana have passed price transparency legislation, and new federal rules now require more hospital price transparency on a national level. Advocates expect strong industry opposition to stiffer measures, like price caps, which recently failed in the Montana legislature.
Other advocates are calling for more scrutiny by state and federal officials of hospital mergers and other anticompetitive practices. Some employers and unions have even resorted to suing hospitals like Sutter Health in California.
Employer Challenges
Employers face a few key barriers to purchasing health care in different and more efficient ways:
Provider Power
Hospitals tend to have much more market power than individual employers, and that power has grown in recent years, enabling them to raise prices. Even very large employers have geographically dispersed workforces, making it hard to exert much leverage over any given hospital. Some employers have tried forming purchasing coalitions to pool their buying power, but they face tricky organizational dynamics and laws that prohibit collusion.
Sophistication
Employers can attempt to lower prices by renegotiating contracts with hospitals or tailoring provider networks, but the work is complicated and rife with tradeoffs. Few employers are sophisticated enough, for example, to assess a provider’s quality or to structure hospital payments in new ways.Employers looking for insurers to help them have limited options, as that industry has also become highly consolidated.
Employee Blowback
Employers say they primarily provide benefits to recruit and retain happy and healthy employees. Many are reluctant to risk upsetting employees by cutting out expensive providers or redesigning benefits in other ways. A recent KFF survey found just 4% of employers had dropped a hospital in order to cut costs.
The Tradeoffs
Employers play a unique role in the United States health care system, and in the lives of the 150 million Americans who get insurance through work. For years, critics have questioned the wisdom of an employer-based health care system, and massive job losses created by the pandemic have reinforced those doubts for many.
Assuming employers do continue to purchase insurance on behalf of millions of Americans, though, focusing on lowering the prices they pay is one promising path to lowering total costs. However, as noted above, hospitals have expressed concern over the financial pressures they may face under these new deals. Complex benefit design strategies, like narrow or tiered networks, also run the risk of harming employees, who may make suboptimal choices or experience cost surprises. Finally, these strategies do not necessarily address other drivers of high costs including drug prices and wasteful care.
The pandemic has shown that it is not existential dangers, but rather everyday economic activities, that reveal the collective, connected character of modern life. Just as a spider’s web crumples when a few strands are broken, so the coronavirus has highlighted the risks arising from our economic interdependence.
CAMBRIDGE – Aristotle was right. Humans have never been atomized individuals, but rather social beings whose every decision affects other people. And now the COVID-19 pandemic is driving home this fundamental point: each of us is morally responsible for the infection risks we pose to others through our own behavior.
In fact, this pandemic is just one of many collective-action problems facing humankind, including climate change, catastrophic biodiversity loss, antimicrobial resistance, nuclear tensions fueled by escalating geopolitical uncertainty, and even potential threats such as a collision with an asteroid.
As the pandemic has demonstrated, however, it is not these existential dangers, but rather everyday economic activities, that reveal the collective, connected character of modern life beneath the individualist façade of rights and contracts.
Those of us in white-collar jobs who are able to work from home and swap sourdough tips are more dependent than we perhaps realized on previously invisible essential workers, such as hospital cleaners and medics, supermarket staff, parcel couriers, and telecoms technicians who maintain our connectivity.
Similarly, manufacturers of new essentials such as face masks and chemical reagents depend on imports from the other side of the world. And many people who are ill, self-isolating, or suddenly unemployed depend on the kindness of neighbors, friends, and strangers to get by.
The sudden stop to economic activity underscores a truth about the modern, interconnected economy: what affects some parts substantially affects the whole. This web of linkages is therefore a vulnerability when disrupted. But it is also a strength, because it shows once again how the division of labor makes everyone better off, exactly as Adam Smith pointed out over two centuries ago.
Today’s transformative digital technologies are dramatically increasing such social spillovers, and not only because they underpin sophisticated logistics networks and just-in-time supply chains. The very nature of the digital economy means that each of our individual choices will affect many other people.
Consider the question of data, which has become even more salient today because of the policy debate about whether digital contact-tracing apps can help the economy to emerge from lockdown faster.
This approach will be effective only if a high enough proportion of the population uses the same app and shares the data it gathers. And, as the Ada Lovelace Institute points out in a thoughtful report, that will depend on whether people regard the app as trustworthy and are sure that using it will help them. No app will be effective if people are unwilling to provide “their” data to governments rolling out the system. If I decide to withhold information about my movements and contacts, this would adversely affect everyone.
Yet, while much information certainly should remain private, data about individuals is only rarely “personal,” in the sense that it is only about them. Indeed, very little data with useful information content concerns a single individual; it is the context – whether population data, location, or the activities of others – that gives it value.
Most commentators recognize that privacy and trust must be balanced with the need to fill the huge gaps in our knowledge about COVID-19. But the balance is tipping toward the latter. In the current circumstances, the collective goal outweighs individual preferences.
But the current emergency is only an acute symptom of increasing interdependence. Underlying it is the steady shift from an economy in which the classical assumptions of diminishing or constant returns to scale hold true to one in which there are increasing returns to scale almost everywhere.
In the conventional framework, adding a unit of input (capital and labor) produces a smaller or (at best) the same increment to output. For an economy based on agriculture and manufacturing, this was a reasonable assumption.
But much of today’s economy is characterized by increasing returns, with bigger firms doing ever better. The network effects that drive the growth of digital platforms are one example of this. And because most sectors of the economy have high upfront costs, bigger producers face lower unit costs.
One important source of increasing returns is the extensive experience-based know-how needed in high-value activities such as software design, architecture, and advanced manufacturing. Such returns not only favor incumbents, but also mean that choices by individual producers and consumers have spillover effects on others.
The pervasiveness of increasing returns to scale, and spillovers more generally, has been surprisingly slow to influence policy choices, even though economists have been focusing on the phenomenon for many years now. The COVID-19 pandemic may make it harder to ignore.
Just as a spider’s web crumples when a few strands are broken, so the pandemic has highlighted the risks arising from our economic interdependence. And now California and Georgia, Germany and Italy, and China and the United States need each other to recover and rebuild. No one should waste time yearning for an unsustainable fantasy.
Once the system can discriminate on a multitude of data points, the commons collapses.
A theme of my writing over the past ten or so years has been the role of data in society. I tend to frame that role anthropologically: How have we adapted to this new element in our society? What tools and social structures have we created in response to its emergence as a currency in our world? How have power structures shifted as a result?
Increasingly, I’ve been worrying a hypothesis: Like a city built over generations without central planning or consideration for much more than fundamental capitalistic values, we’ve architected an ecosystem around data that is not only dysfunctional, it’s possibly antithetical to the core values of democratic society. Houston, it seems, we really do have a problem.
Last week ProPublica published a story titled Health Insurers Are Vacuuming Up Details About You — And It Could Raise Your Rates. It’s the second in an ongoing series the investigative unit is doing on the role of data in healthcare. I’ve been watching this story develop for years, and ProPublica’s piece does a nice job of framing the issue. It envisions “a future in which everything you do — the things you buy, the food you eat, the time you spend watching TV — may help determine how much you pay for health insurance.”
Unsurprisingly, the health industry has developed an insatiable appetite for personal data about the individuals it covers. Over the past decade or so, all of our quotidian activities (and far more) have been turned into data, and that data can and is being sold to the insurance industry:
“The companies are tracking your race, education level, TV habits, marital status, net worth. They’re collecting what you post on social media, whether you’re behind on your bills, what you order online. Then they feed this information into complicated computer algorithms that spit out predictions about how much your health care could cost them.”
HIPPA, the regulatory framework governing health information in the United States, only covers and protects medical data – not search histories, streaming usage, or grocery loyalty data. But if you think your search, video, and food choices aren’t related to health, well, let’s just say your insurance company begs to differ.
Lest we dive into a rabbit hole about the corrosive combination of healthcare profit margins with personal data (ProPublica’s story does a fine job of that anyway), I want to pull back and think about what’s really going on here.
The Tragedy of the Commons
One of the most fundamental tensions in an open society is the potential misuse of resources held “in common” – resources to which all individuals have access. Garrett Hardin’s 1968 essay on the subject, “The Tragedy of the Commons,” explores this tension, concluding that the problem of human overpopulation has no technical solution. (A technical solution is one that does not require a shift in human values or morality (IE, a political solution), but rather can be fixed by application of science and/or engineering.) Hardin’s essay has become one of the most cited works in social science – the tragedy of the commons is a facile concept that applies to countless problems across society.
In the essay, Hardin employs a simple example of a common grazing pasture, open to all who own livestock. The pasture, of course, can only support a finite number of cattle. But as Hardin argues, cattle owners are financially motivated to graze as many cattle as they possibly can, driving the number of grass munchers beyond the land’s capacity, ultimately destroying the commons. “Freedom in a commons brings ruin to all,” he concludes, delivering an intellectual middle finger to Smith’s “invisible hand” in the process.
So what does this have to do with healthcare, data, and the insurance industry? Well, consider how the insurance industry prices its policies. Insurance has always been a data-driven business – it’s driven by actuarial risk assessment, a statistical method that predicts the probability of a certain event happening. Creating and refining these risk assessments lies at the heart of the insurance industry, and until recently, the amount of data informing actuarial models has been staggeringly slight. Age, location, and tobacco use are pretty much how policies are priced under Obamacare, for example. Given this paucity, one might argue that it’s utterly a *good* thing that the insurance industry is beefing up its databases. Right?
Perhaps not. When a population is aggregated on high-level data points like age and location, we’re essentially being judged on a simple shared commons – all 18 year olds who live in Los Angeles are being treated essentially the same, regardless if one person has a lurking gene for cancer and another will live without health complications for decades. In essence, we’re sharing the load of public health in common – evening out the societal costs in the process.
But once the system can discriminate on a multitude of data points, the commons collapses, devolving into a system rewarding whoever has the most profitable profile. That 18-year old with flawless genes, the right zip code, an enviable inheritance, and all the right social media habits will pay next to nothing for health insurance. But the 18 year old with a mutated BRCA1 gene, a poor zip code, and a proclivity to sit around eating Pringles while playing Fortnite? That teenager is not going to be able to afford health insurance.
Put another way, adding personalized data to the insurance commons destroys the fabric of that commons. Healthcare has been resistant to this force until recently, but we’re already seeing the same forces at work in other aspects of our previously shared public goods.
A public good, to review, is defined as “a commodity or service that is provided without profit to all members of a society, either by the government or a private individual or organization.” A good example is public transportation. The rise of data-driven services like Uber and Lyft have been a boon for anyone who can afford these services, but the unforeseen externalities are disastrous for the public good. Ridership, and therefore revenue, falls for public transportation systems, which fall into a spiral of neglect and decay. Our public streets become clogged with circling rideshare drivers, roadway maintenance costs skyrocket, and – perhaps most perniciously – we become a society of individuals who forget how to interact with each other in public spaces like buses, subways, and trolley cars.
Once you start to think about public goods in this way, you start to see the data-driven erosion of the public good everywhere. Our public square, where we debate political and social issues, has become 2.2 billion data-driven Truman Shows, to paraphrase social media critic Roger McNamee. Retail outlets, where we once interacted with our fellow citizens, are now inhabited by armies of Taskrabbits and Instacarters. Public education is hollowed out by data-driven personalized learning startups like Alt School, Khan Academy, or, let’s face it, YouTube how to videos.
We’re facing a crisis of the commons – of the public spaces we once held as fundamental to the functioning of our democratic society. And we have data-driven capitalism to blame for it.
Now, before you conclude that Battelle has become a neo-luddite, know that I remain a massive fan of data-driven business. However, if we fail to re-architect the core framework of how data flows through society – if we continue to favor the rights of corporations to determine how value flows to individuals absent the balancing weight of the public commons – we’re heading down a path of social ruin. ProPublica’s warning on health insurance is proof that the problem is not limited to Facebook alone. It is a problem across our entire society. It’s time we woke up to it.
So what do we do about it? That’ll be the focus of a lot of my writing going forward. As Hardin writes presciently in his original article, “It is when the hidden decisions are made explicit that the arguments begin. The problem for the years ahead is to work out an acceptable theory of weighting.” In the case of data-driven decisioning, we can no longer outsource that work to private corporations with lofty sounding mission statements, whether they be in healthcare, insurance, social media, ride sharing, or e-commerce.











CAMBRIDGE – Aristotle was right. Humans have never been atomized individuals, but rather social beings whose every decision affects other people. And now the COVID-19 pandemic is driving home this fundamental point: each of us is morally responsible for the infection risks we pose to others through our own behavior.
In fact, this pandemic is just one of many collective-action problems facing humankind, including climate change, catastrophic biodiversity loss, antimicrobial resistance, nuclear tensions fueled by escalating geopolitical uncertainty, and even potential threats such as a collision with an asteroid.
As the pandemic has demonstrated, however, it is not these existential dangers, but rather everyday economic activities, that reveal the collective, connected character of modern life beneath the individualist façade of rights and contracts.
Those of us in white-collar jobs who are able to work from home and swap sourdough tips are more dependent than we perhaps realized on previously invisible essential workers, such as hospital cleaners and medics, supermarket staff, parcel couriers, and telecoms technicians who maintain our connectivity.
Similarly, manufacturers of new essentials such as face masks and chemical reagents depend on imports from the other side of the world. And many people who are ill, self-isolating, or suddenly unemployed depend on the kindness of neighbors, friends, and strangers to get by.
The sudden stop to economic activity underscores a truth about the modern, interconnected economy: what affects some parts substantially affects the whole. This web of linkages is therefore a vulnerability when disrupted. But it is also a strength, because it shows once again how the division of labor makes everyone better off, exactly as Adam Smith pointed out over two centuries ago.
Today’s transformative digital technologies are dramatically increasing such social spillovers, and not only because they underpin sophisticated logistics networks and just-in-time supply chains. The very nature of the digital economy means that each of our individual choices will affect many other people.
Consider the question of data, which has become even more salient today because of the policy debate about whether digital contact-tracing apps can help the economy to emerge from lockdown faster.
This approach will be effective only if a high enough proportion of the population uses the same app and shares the data it gathers. And, as the Ada Lovelace Institute points out in a thoughtful report, that will depend on whether people regard the app as trustworthy and are sure that using it will help them. No app will be effective if people are unwilling to provide “their” data to governments rolling out the system. If I decide to withhold information about my movements and contacts, this would adversely affect everyone.
Yet, while much information certainly should remain private, data about individuals is only rarely “personal,” in the sense that it is only about them. Indeed, very little data with useful information content concerns a single individual; it is the context – whether population data, location, or the activities of others – that gives it value.
Most commentators recognize that privacy and trust must be balanced with the need to fill the huge gaps in our knowledge about COVID-19. But the balance is tipping toward the latter. In the current circumstances, the collective goal outweighs individual preferences.
But the current emergency is only an acute symptom of increasing interdependence. Underlying it is the steady shift from an economy in which the classical assumptions of diminishing or constant returns to scale hold true to one in which there are increasing returns to scale almost everywhere.
In the conventional framework, adding a unit of input (capital and labor) produces a smaller or (at best) the same increment to output. For an economy based on agriculture and manufacturing, this was a reasonable assumption.
But much of today’s economy is characterized by increasing returns, with bigger firms doing ever better. The network effects that drive the growth of digital platforms are one example of this. And because most sectors of the economy have high upfront costs, bigger producers face lower unit costs.
One important source of increasing returns is the extensive experience-based know-how needed in high-value activities such as software design, architecture, and advanced manufacturing. Such returns not only favor incumbents, but also mean that choices by individual producers and consumers have spillover effects on others.
The pervasiveness of increasing returns to scale, and spillovers more generally, has been surprisingly slow to influence policy choices, even though economists have been focusing on the phenomenon for many years now. The COVID-19 pandemic may make it harder to ignore.
Just as a spider’s web crumples when a few strands are broken, so the pandemic has highlighted the risks arising from our economic interdependence. And now California and Georgia, Germany and Italy, and China and the United States need each other to recover and rebuild. No one should waste time yearning for an unsustainable fantasy.